Архитектура платформы
Компоненты
В основе платформы лежит клиент-серверная архитектура, которая может быть условно представлена в виде трех программных уровней: сервер-облако, клиентский и вычислительный.
На схеме представлена архитектура платформы с двумя внешними вычислительными кластерами.
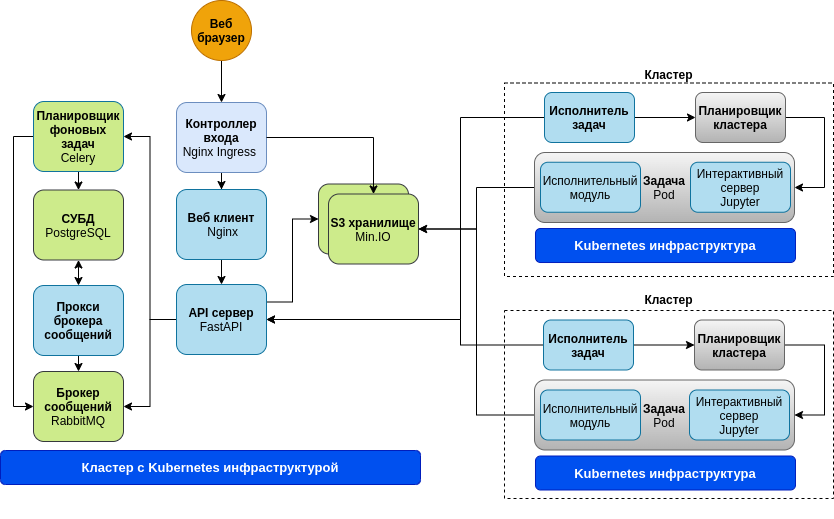
Клиентский уровень - веб приложение, обеспечивающие взаимодействие пользователей с сервисами платформы. Веб приложение разработано с использованием языка программирования JavaScript и фреймворков Quasar 2 и Vue.js 3 и развернут на веб сервере NginX.
Включает в себя:
- Веб клиент
Сервер-облако - программно-аппаратная инфраструктура, которая включает в себя комплекс прикладного и системного программного обеспечения, реализующая основные сервисы платформы и предоставляющая к ним удаленный доступ в интернет-среде. Сервер-облако является основным самодостаточными элементом платформы и может функционировать как изолированно в рамках отдельных организационных структур (компаний), так и совместно реализуя сложные распределенные последовательности обработки данных.
В него входят:
- Контроллер доступа - контроллер доступа из сети Интернет Nginx Ingress Controller
- API сервер - REST сервер на основе Fast API
- Планировщик фоновых задач - менеджер запуска длительных фоновых задач на Celery
- Брокер сообщений - брокер обмена сообщениями между элементами платформы на RabbitMQ
- СУБД - база данных PostgreSQL 13
- Прокси брокера сообщений - прокси модуль обмена сообщениями между СУБД и брокером сообщений
- S3 хранилище - объектное (файловое) хранилище данных MinIO
API сервер - базовый компонент, реализующий основную бизнес логику функционирования платформы и обработки пользовательских запросов. Взаимодействие с сервером реализуется с помощью специального открытого API, которое может быть использовано как в программном обеспечении платформы так и в программных продуктах сторонних разработчиков.
Брокер сообщений создает единое пространство обмена сообщениями между серверными компонентами платформы и снижает нагрузку на системы реляционного хранения данных. Для оптимизации обмена сообщений платформа использует дополнительный прокси брокера сообщений (Message broker proxy).
Сервер базы данных используется для хранения служебной информации платформы, структуры и метаинформации графов обработки, а также непосредственного хранения пользовательских данных небольших объемов. Обработчик фоновых задача на основе Celery используется для запуска длительных асинхронных служебных процедур.
S3 хранилище/сервер используется для хранение различных объектных (файловых) данных.
Вычислительный уровень (кластер) - высокопроизводительная программно-аппаратная инфраструктура, предназначенная для непосредственного выполнения пользовательских исполнительных модулей (скрипты, программы) узлов. Вычислительные кластера могут быть как интегрированными в сервер-облако так и кластерами общего пользования входящими в общедоступные вычислительные ресурсы.
В него входят:
- Исполнитель задач - планировщик запуска задач
- Задача - выполняемая задача в среде Kubernetes
- Интерактивный сервер - опциональный модуль интерактивного доступа к задаче на основе Jupyter сервера
Исполнитель задач - специальный программный модуль, который отслеживает появления новых данных (пакетов для обработки) через API сервер и отправляет их на выполнение в планировщик задач конкретного кластера.
По умолчанию задачи выполняются в неинтерактивном режиме. Также платформа предоставляет возможность запуска задачи в интерактивном режиме, при этом в контейнере пользователя дополнительно запускается Jupyter сервер, с которым пользователь может взаимодействовать обычным образом.
Среда исполнения (контейнеры)
Общее
Все компоненты платформы предназначены для запуска в Docker контейнере и рекомендуется осуществлять их запуск в среде Kubernetes.
Все задания запускаемые пользователем исполняются в Docker контейнерах, которые в свою очередь запускаются на подключенных к платформе Kubernetest кластерах.
Использование Docker контейнеров как среды исполнения позволяет осуществлять изоляцию выполняемых пользовательских вычислительных задач, а пользователю самостоятельно настраивать среду исполнения под требования своих прикладных задач.
Для каждого конкретного узла графа пользователь может указать необходимую среду исполнения (Докер образ) с указанием конкретного репозитория в сети Интернет, с которого платформа должна загрузить указанный образ. Например, можно использовать хранилище Докер образов DockerHub.
Доступ к образу на чтение должен осуществлять без дополнительной авторизации. После первого запуска образ будет закеширован на промежуточных прокси-реестрах платформы на уровне вычислительных кластеров, а также в локальных хранилищах образов Kubernetes на узлах.
Исполняемые контейнеры должны содержать в себя специальную библиотеку job.py. Для этого образ должен быть создан из доступных базовых образов платформы или библиотека должна быть установлена самостоятельно (см. раздел Контейнеры).
OpenCL
Поддерживается счет только на специальных узлах кластера с использованием специализированных контейнеров. При использовании необходимо указать количество требуемых карт в поле ГПУ в вкладке Контейнер панели узла соответствующего узла.
CUDA
Поддерживается счет только на специальных узлах кластера с использованием специализированных контейнеров. При использовании необходимо указать количество требуемых карт в поле ГПУ в вкладке Контейнер панели узла соответствующего узла.